大分類、中分類、小分類などのカテゴリー (分類) を列に持つテーブルのデータを、ツリー状に階層を表現して1つの列として取得するSQLの作成方法です。
取得した結果のデータは以下のようなイメージです。
- プログラミング
- C#
- LINQの便利なメソッド…
- 式木をメソッドの引数として使いこなす技…
- C#7.0の新機能一覧…
- JavaScript
- Promiseで非同期処理を簡単に実装…
- Node.jsでサーバーサイドプログラミング…
- C#
- データベース
- SQL Server
- 照合順序とサロゲートペア…
- 接続文字列のいろいろ…
- リンクサーバーの設定方法…
- MySQL
- ページデータを取得する…
- 日付関数を使いこなす…
- SQL Server
わざわざSQLで1つの列に取得しなくてもプログラムで制御すればいいんですが、データベースのビューとして作成してほしいという依頼があった時になどには役に立つかもしれません。
使用するテーブル
ここでは例として、商品情報を管理するテーブルがあるとします。
商品テーブルの列には [商品番号] と [商品名] があり、分類として [大分類コード] と [小分類コード] を持ちます。
大分類と小分類は [分類コード] と [分類名] を持つマスターテーブルがあり、商品テーブルに紐づきます。
テーブル
| 論理名 | 物理名 |
|---|---|
| 商品テーブル | TBL_SHOHIN |
| 大分類マスタ | TBL_DAIBUNRUI |
| 小分類マスタ | TBL_SHOBUNRUI |
テーブルの列定義
商品テーブル (TBL_SHOHIN)
| No | 論理名 | 物理名 |
|---|---|---|
| 1 | 商品番号 | SHOHIN_NO |
| 2 | 商品名 | SHOHIN_NAME |
| 3 | 大分類コード | DAIBUNRUI_CODE |
| 4 | 小分類コード | SHOBUNRUI_CODE |
大分類マスタ (TBL_DAIBUNRUI)
| No | 論理名 | 物理名 |
|---|---|---|
| 1 | 大分類コード | DAIBUNRUI_CODE |
| 2 | 大分類名 | DAIBUNRUI_NAME |
小分類マスタ (TBL_SHOBUNRUI)
| No | 論理名 | 物理名 |
|---|---|---|
| 1 | 小分類コード | SHOBUNRUI_CODE |
| 2 | 小分類名 | SHOBUNRUI_NAME |
商品テーブルの大分類コードは必ず指定され、小分類コードの指定は任意(小分類がない商品の登録を許可する)とします。
テーブルの作成
テーブルの CREATE 文です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
-- 商品テーブル DROP TABLE IF EXISTS TBL_SHOHIN; GO CREATE TABLE TBL_SHOHIN( SHOHIN_NO int NOT NULL, SHOHIN_NAME varchar(100) COLLATE Japanese_BIN NOT NULL, DAIBUNRUI_CODE varchar(3) COLLATE Japanese_BIN NOT NULL, SHOBUNRUI_CODE varchar(3) COLLATE Japanese_BIN NULL, CONSTRAINT PK_TBL_SHOHIN PRIMARY KEY CLUSTERED ( SHOHIN_NO ASC ) ) ON [PRIMARY]; GO -- 大分類マスタ DROP TABLE IF EXISTS TBL_DAIBUNRUI; GO CREATE TABLE dbo.TBL_DAIBUNRUI( DAIBUNRUI_CODE varchar(3) COLLATE Japanese_BIN NOT NULL, DAIBUNRUI_NAME varchar(50) COLLATE Japanese_BIN NOT NULL, CONSTRAINT PK_TBL_DAIBUNRUI PRIMARY KEY CLUSTERED ( DAIBUNRUI_CODE ASC ) ) ON [PRIMARY]; GO -- 小分類マスタ DROP TABLE IF EXISTS TBL_SHOBUNRUI; GO CREATE TABLE dbo.TBL_SHOBUNRUI( SHOBUNRUI_CODE varchar(3) COLLATE Japanese_BIN NOT NULL, SHOBUNRUI_NAME varchar(50) COLLATE Japanese_BIN NOT NULL, CONSTRAINT PK_TBL_SHOBUNRUI PRIMARY KEY CLUSTERED ( SHOBUNRUI_CODE ASC ) ) ON [PRIMARY]; GO |
テーブルに登録されているデータ
商品テーブル (TBL_SHOHIN)
| 商品番号 | 商品名 | 大分類コード | 小分類コード |
|---|---|---|---|
| 1 | 商品1 | 001 | 002 |
| 2 | 商品2 | 002 | 001 |
| 3 | 商品3 | 002 | 002 |
| 4 | 商品4 | 003 | |
| 5 | 商品5 | 003 | 003 |
| 6 | 商品6 | 001 | |
| 7 | 商品7 | 003 | 002 |
| 8 | 商品8 | 001 | 001 |
| 9 | 商品9 | 002 | 002 |
| 10 | 商品10 | 002 | 003 |
| 11 | 商品11 | 001 | 002 |
| 12 | 商品12 | 003 |
大分類マスタ (TBL_DAIBUNRUI)
| 大分類コード | 大分類名 |
|---|---|
| 001 | 大分類1 |
| 002 | 大分類2 |
| 003 | 大分類3 |
小分類マスタ (TBL_SHOBUNRUI)
| 小分類コード | 小分類名 |
|---|---|
| 001 | 小分類1 |
| 002 | 小分類2 |
| 003 | 小分類3 |
データの登録
テーブルの INSERT 文です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
-- 商品テーブル INSERT INTO TBL_SHOHIN (SHOHIN_NO, SHOHIN_NAME, DAIBUNRUI_CODE, SHOBUNRUI_CODE) VALUES (1, '商品1', '001', '002'), (2, '商品2', '002', '001'), (3, '商品3', '002', '002'), (4, '商品4', '003', NULL), (5, '商品5', '003', '003'), (6, '商品6', '001', NULL), (7, '商品7', '003', '002'), (8, '商品8', '001', '001'), (9, '商品9', '002', '002'), (10, '商品10', '002', '003'), (11, '商品11', '001', '002'), (12, '商品12', '003', NULL); -- 大分類マスタ INSERT INTO TBL_DAIBUNRUI (DAIBUNRUI_CODE, DAIBUNRUI_NAME) VALUES ('001', '大分類1'), ('002', '大分類2'), ('003', '大分類3'); -- 小部類マスタ INSERT INTO TBL_SHOBUNRUI (SHOBUNRUI_CODE, SHOBUNRUI_NAME) VALUES ('001', '小分類1'), ('002', '小分類2'), ('003', '小分類3'); |
上記のテーブルへのデータのインサートは、複数のレコードを1回のSQLで一括挿入する形式で記述しています。
1回のINSERTで複数行のレコードをテーブルに一括で挿入する方法については、以下の記事を参照してください。


SQLを作成していく
商品テーブルのデータを分解
まずは商品テーブルのデータを大分類、小分類、商品に分解して取得します。
大分類データの取得
|
1 2 3 4 5 6 |
-- 大分類の一覧を取得 SELECT DISTINCT 0 AS KAISO_LEVEL, DAIBUNRUI_CODE FROM TBL_SHOHIN |
小分類データの取得
|
1 2 3 4 5 6 7 8 9 |
-- 小分類の一覧を取得 SELECT DISTINCT 1 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE FROM TBL_SHOHIN WHERE ISNULL(SHOBUNRUI_CODE, '') <> '' |
商品データの取得
|
1 2 3 4 5 6 7 8 9 |
-- 商品の一覧を取得 SELECT 2 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, SHOHIN_NO, SHOHIN_NAME FROM TBL_SHOHIN |
大分類と小分類をDISTINCTで重複行を取り除いて取得します。
小分類を取得する場合は小分類が登録されているデータのみ取得するために、WHEREで有効な行のみを取得します。(大分類は必ず登録される前提があるのでそのまま取得しています。)
それぞれのデータを取得する際に階層化できるように [KAISO_LEVEL] という列を追加しておきます。ここでは大分類を「0」小分類を「1」商品を「2」で追加しています。
分解したデータを結合
次に分解して取得したデータをUNIONで結合します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
-- 大分類の一覧を取得 SELECT DISTINCT 0 AS KAISO_LEVEL, DAIBUNRUI_CODE, NULL AS SHOBUNRUI_CODE, NULL AS SHOHIN_NO, NULL AS SHOHIN_NAME FROM TBL_SHOHIN UNION -- 小分類の一覧を取得 SELECT DISTINCT 1 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, NULL AS SHOHIN_NO, NULL AS SHOHIN_NAME FROM TBL_SHOHIN WHERE ISNULL(SHOBUNRUI_CODE, '') <> '' UNION -- 商品の一覧を取得 SELECT 2 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, SHOHIN_NO, SHOHIN_NAME FROM TBL_SHOHIN |
この時、大分類と小分類には商品データにある列をNULLで追加しておきます。(大分類の場合は小分類と商品コード、商品名を、小分類の場合は商品コード、商品名をNULLで追加します。)
インデントとノードの取得
UNIONで結合したSQLをもとに、インデントに使用する文字列とツリー表示するノード(各データの名前)の列を追加します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
SELECT -- インデントは全角スペースで表現 REPLICATE(' ', CASE KAISO_LEVEL -- 商品レコードの小分類が未登録の場合は階層を1つ上げる WHEN 2 THEN CASE WHEN ISNULL(TBL_SHOHIN.SHOBUNRUI_CODE, '') = '' THEN KAISO_LEVEL - 1 ELSE KAISO_LEVEL END ELSE KAISO_LEVEL END) AS INDENT, TBL_SHOHIN.KAISO_LEVEL, TBL_SHOHIN.SHOHIN_NO, TBL_SHOHIN.DAIBUNRUI_CODE, TBL_SHOHIN.SHOBUNRUI_CODE, TBL_SHOHIN.SHOHIN_NAME, -- ツリーに表示するノードの名前 CASE KAISO_LEVEL WHEN 0 THEN TBL_DAIBUNRUI.DAIBUNRUI_NAME WHEN 1 THEN TBL_SHOBUNRUI.SHOBUNRUI_NAME ELSE TBL_SHOHIN.SHOHIN_NAME END AS NODE_NAME FROM ( -- 大分類の一覧を取得 SELECT DISTINCT 0 AS KAISO_LEVEL, DAIBUNRUI_CODE, NULL AS SHOBUNRUI_CODE, NULL AS SHOHIN_NO, NULL AS SHOHIN_NAME FROM TBL_SHOHIN UNION -- 小分類の一覧を取得 SELECT DISTINCT 1 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, NULL AS SHOHIN_NO, NULL AS SHOHIN_NAME FROM TBL_SHOHIN WHERE ISNULL(SHOBUNRUI_CODE, '') <> '' UNION -- 商品の一覧を取得 SELECT 2 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, SHOHIN_NO, SHOHIN_NAME FROM TBL_SHOHIN ) AS TBL_SHOHIN -- 大分類マスタを結合 LEFT OUTER JOIN TBL_DAIBUNRUI ON TBL_SHOHIN.DAIBUNRUI_CODE = TBL_DAIBUNRUI.DAIBUNRUI_CODE -- 小分類マスタを結合 LEFT OUTER JOIN TBL_SHOBUNRUI ON TBL_SHOHIN.SHOBUNRUI_CODE = TBL_SHOBUNRUI.SHOBUNRUI_CODE |
階層レベルからREPLICATE関数を使ってインデント文字列を作成します。この時、小分類が登録されていない商品データの階層レベルは1つ上げておきます。(小分類がない商品は大分類に直接ぶら下がるので、階層レベルを2から1に変更します。)
大分類マスタと小分類マスタを LEFT OUTER JOIN で結合して、各マスタの分類名を取得します。
取得した分類名と商品名をCASE式を使って1つの列にまとめ、ノードに表示する名前を作成します。階層レベルが「0」の場合は大分類名を「1」の場合は小分類名を「2」の場合は商品名を取得します。
ここではインデント文字列を [INDENT] という列で追加し、ノードとして表示する名前を [NODE_NAME] という列で追加しています。


ツリー状に表示する
最後に追加したインデント文字列とノード名の列を1つの列に合わせて取得します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 |
SELECT -- インデント文字列とノード名を1つの列に合わせる INDENT + NODE_NAME AS TREE_ITEM FROM ( SELECT -- インデントは全角スペースで表現 REPLICATE(' ', CASE KAISO_LEVEL -- 商品レコードの小分類が未登録の場合は階層を1つ上げる WHEN 2 THEN CASE WHEN ISNULL(TBL_SHOHIN.SHOBUNRUI_CODE, '') = '' THEN KAISO_LEVEL - 1 ELSE KAISO_LEVEL END ELSE KAISO_LEVEL END) AS INDENT, TBL_SHOHIN.KAISO_LEVEL, TBL_SHOHIN.SHOHIN_NO, TBL_SHOHIN.DAIBUNRUI_CODE, TBL_SHOHIN.SHOBUNRUI_CODE, TBL_SHOHIN.SHOHIN_NAME, -- ツリーに表示するノードの名前 CASE KAISO_LEVEL WHEN 0 THEN TBL_DAIBUNRUI.DAIBUNRUI_NAME WHEN 1 THEN TBL_SHOBUNRUI.SHOBUNRUI_NAME ELSE TBL_SHOHIN.SHOHIN_NAME END AS NODE_NAME FROM ( -- 大分類の一覧を取得 SELECT DISTINCT 0 AS KAISO_LEVEL, DAIBUNRUI_CODE, NULL AS SHOBUNRUI_CODE, NULL AS SHOHIN_NO, NULL AS SHOHIN_NAME FROM TBL_SHOHIN UNION -- 小分類の一覧を取得 SELECT DISTINCT 1 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, NULL AS SHOHIN_NO, NULL AS SHOHIN_NAME FROM TBL_SHOHIN WHERE ISNULL(SHOBUNRUI_CODE, '') <> '' UNION -- 商品の一覧を取得 SELECT 2 AS KAISO_LEVEL, DAIBUNRUI_CODE, SHOBUNRUI_CODE, SHOHIN_NO, SHOHIN_NAME FROM TBL_SHOHIN ) AS TBL_SHOHIN -- 大分類マスタを結合 LEFT OUTER JOIN TBL_DAIBUNRUI ON TBL_SHOHIN.DAIBUNRUI_CODE = TBL_DAIBUNRUI.DAIBUNRUI_CODE -- 小分類マスタを結合 LEFT OUTER JOIN TBL_SHOBUNRUI ON TBL_SHOHIN.SHOBUNRUI_CODE = TBL_SHOBUNRUI.SHOBUNRUI_CODE ) AS TBL_SHOHIN ORDER BY TBL_SHOHIN.DAIBUNRUI_CODE, TBL_SHOHIN.SHOBUNRUI_CODE, TBL_SHOHIN.SHOHIN_NO |
ORDER BYでソート順を、大分類+小分類+商品番号の昇順で取得してツリー状に表示します。
取得結果のデータ
上記のSQLを実行した結果は以下のようになります。
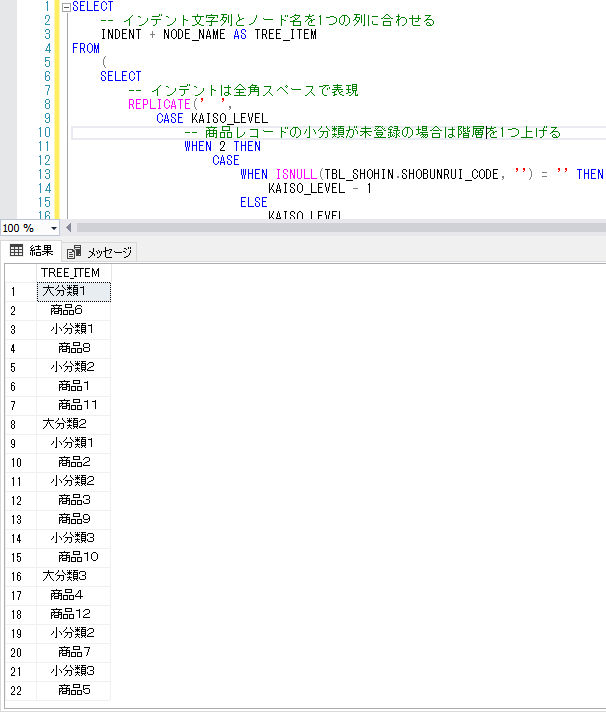
| ツリーノード |
|---|
| 大分類1 |
| 商品6 |
| 小分類1 |
| 商品8 |
| 小分類2 |
| 商品1 |
| 商品11 |
| 大分類2 |
| 小分類1 |
| 商品2 |
| 小分類2 |
| 商品3 |
| 商品9 |
| 小分類3 |
| 商品10 |
| 大分類3 |
| 商品4 |
| 商品12 |
| 小分類2 |
| 商品7 |
| 小分類3 |
| 商品5 |
最近はSQLでデータを加工して取得すると業務ロジックが分散することになるので、プログラム内でデータの加工をするようにしてほしいという客先の開発者も増えてきました。しかし、まだまだSQLが大好きな開発者の方が大勢いらっしゃるので、今回の記事でご紹介した内容は、きっとどこかで役に立つと思います。
